
XSStrike是一款优秀的开源xss漏洞扫描器。
前言
scan扫描作为XSStrike扫描器的核心部分,具有dom检测、waf检测、参数发现等功能,在上篇已经分析过这些功能的实现方法。接下来分析scan扫描的处理流程,分为如下部分:
- 网页解析
- 过滤检测
- Payload生成
- XSS验证
网页解析
在开始之前会根据命令配置进行dom检测、参数发现和waf检测,在上篇已经做了分析,如下:
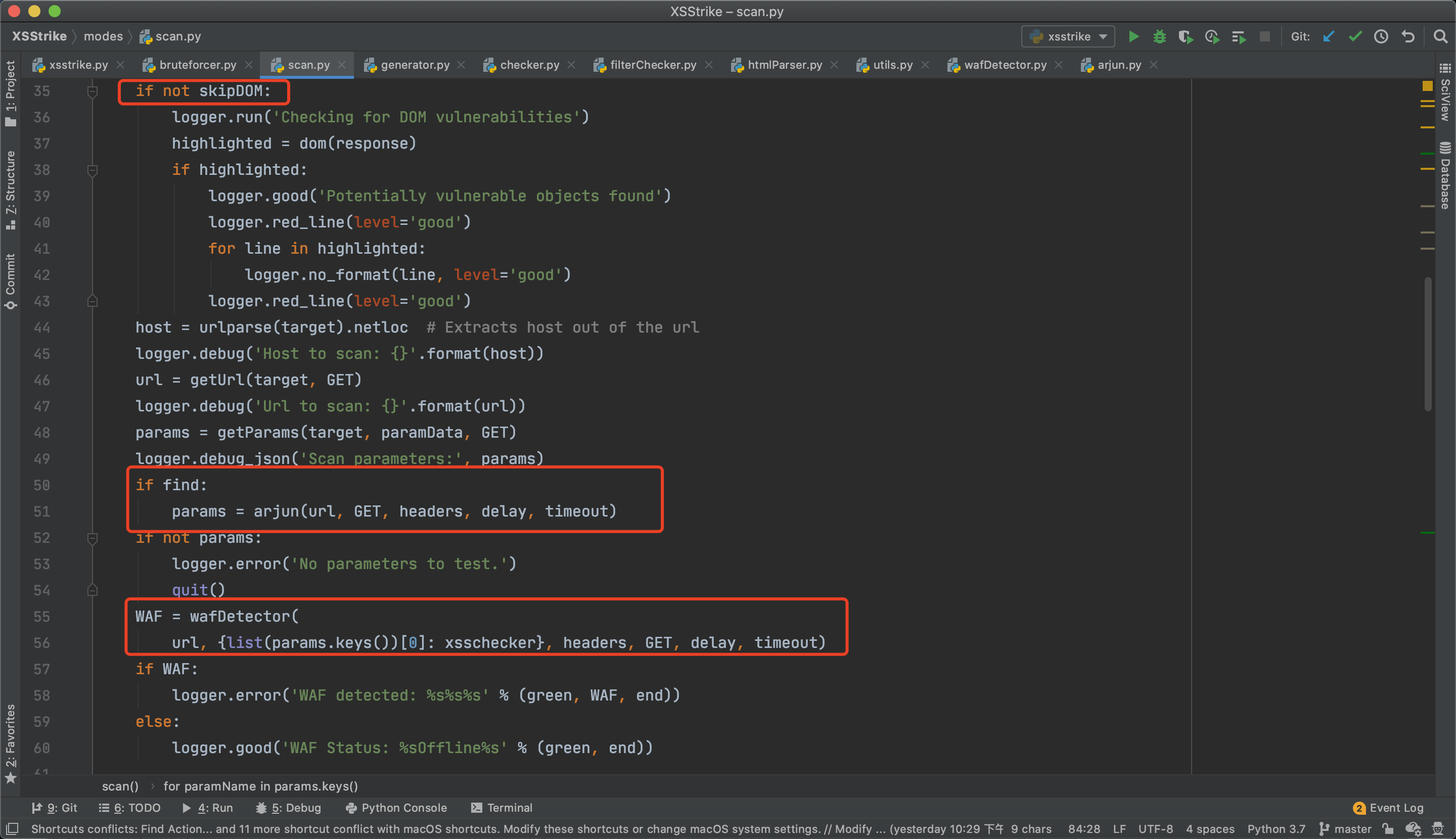
接下来扫描器会进行参数替换,并将相应报文传入htmlParser分析,如下:

接下来分析下htmlParser函数的实现方式,代码如下:
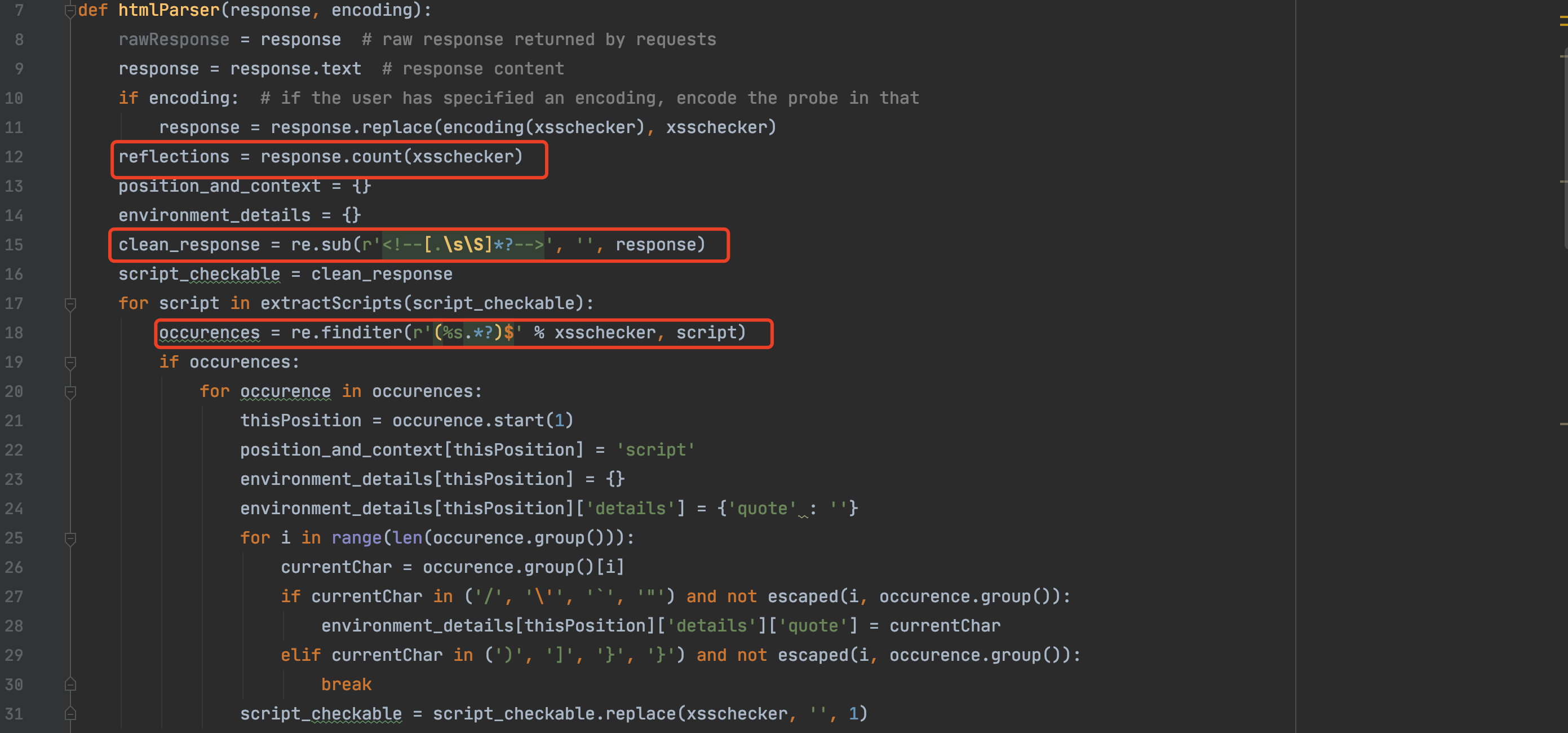
首先会在响应报文中统计xss标记,接下来会对响应报文进行处理,去除注释标记,然后对所有<script>进行遍历,用于发现是否出现的script标签之中。
如果发现存在的话,position_and_context变量会记录出现位置以及出现的位置,此处则为script标签之中,environment_details则会记录闭合方式。
通过replace函数为发现的xss标记做替换为空处理,防止下次重复处理。
如果未在script标签中发现xss标记,则会进行下一阶段的处理,用于检测是否在标签之中出现,如a、div等标签,代码如下:
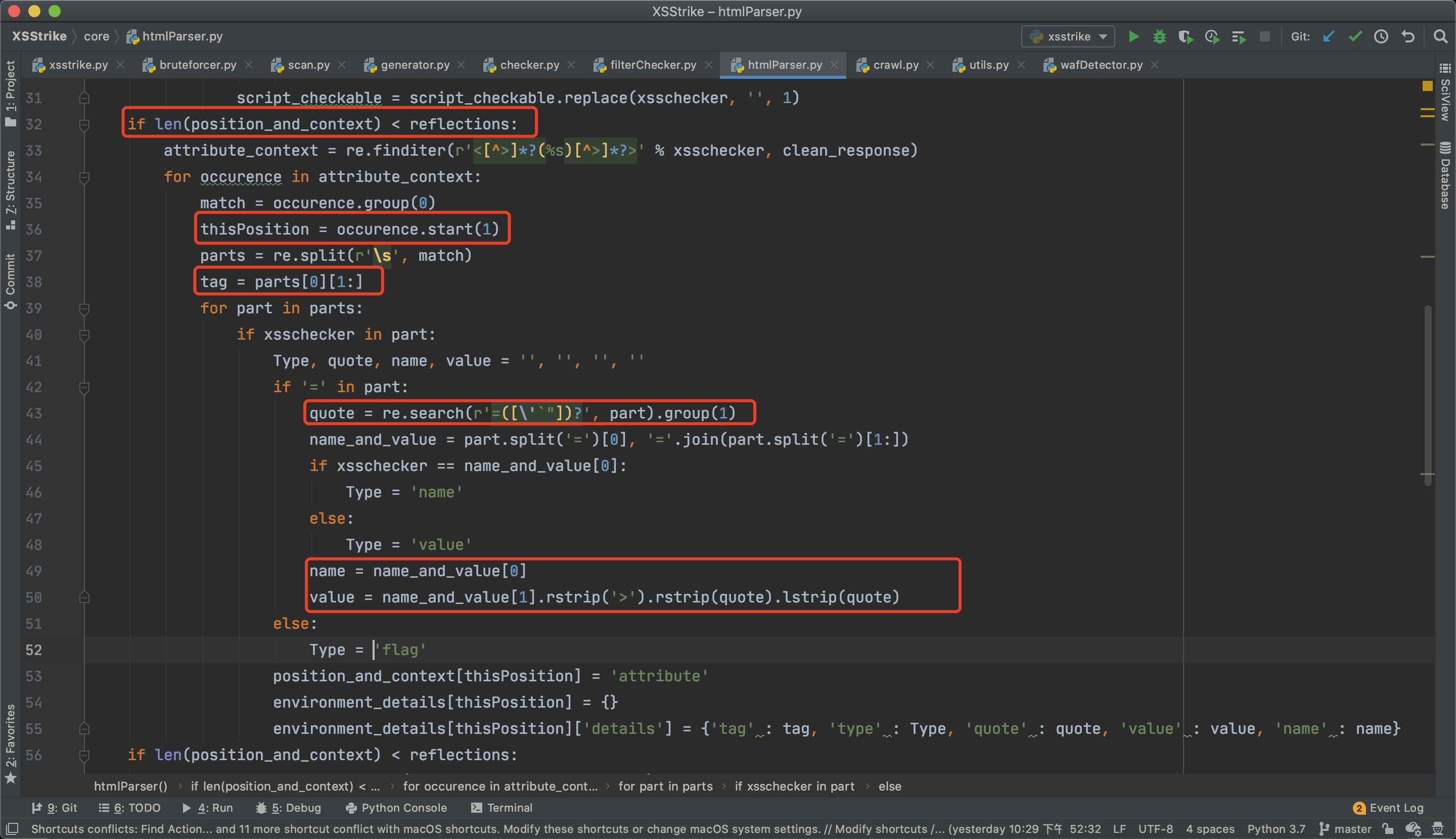
首先处理之前会先进行判断,用于判断是否所有xss已经被处理,如果已经处理则不会进入循环,提高运行效率。
同样的也会记录出现位置,记录是在哪个标签中出现的,以及闭合方式、name、value值。
当标签也没有检测到xss标记之后,会进行全局的查找,代码如下:

当在html页面发现时,会做一个html标记,如果还没有发现,有可能出现在注释之中,加下来会对注释进行检测:

检测的为原始报文response,检测到之后会做一个commnet标记。
当分析完毕之后,会将分析结果存入database字典,然后返回,如下:
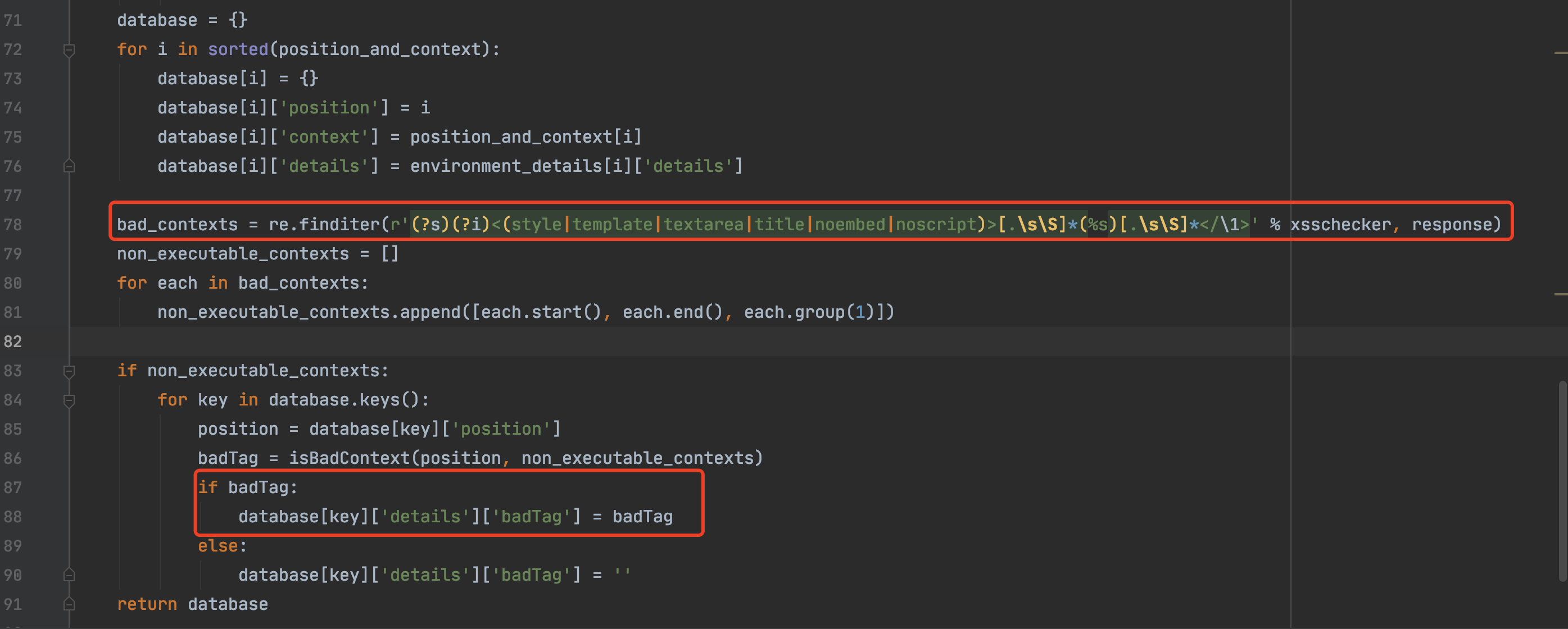
最后,还有一个bad_tag检测,如果检测到标签为上面正则中的任何一种形式之后,会做一个badTag标记。
过滤检测
经过htmlParser函数解析之后,通过occurences变量传入filterChecker函数,如下:
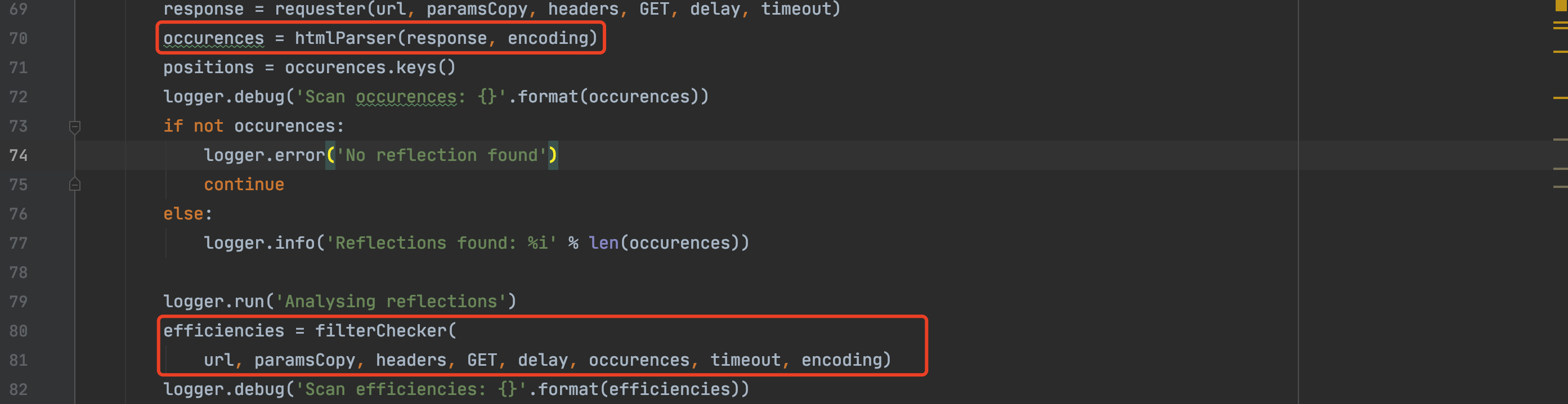
filterChecker函数处理逻辑如下:
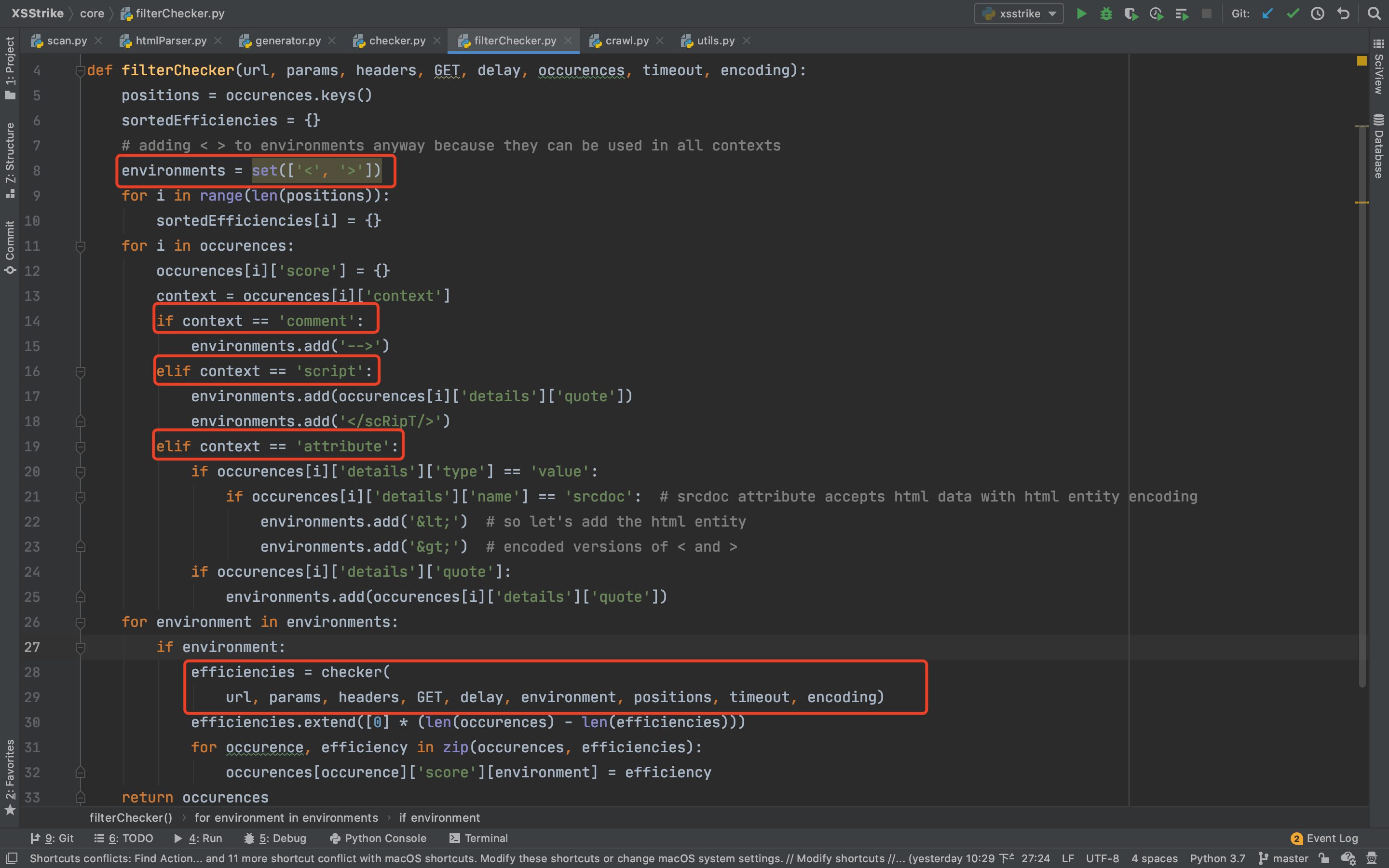
首先定义两个初始探测变量,<和>。
如果xss标记出现在注释中,则会加入-->进行注释闭合测试。
如果出现在script中,会将闭合标记和混淆的script标签加入。
如果出现在属性标签之中,为srcdoc标签的话则会加入实体编码,因为srcdoc支持对实体编码的解释,然后加如闭合标记。
接下来调用checker函数进行检测,代码如下:
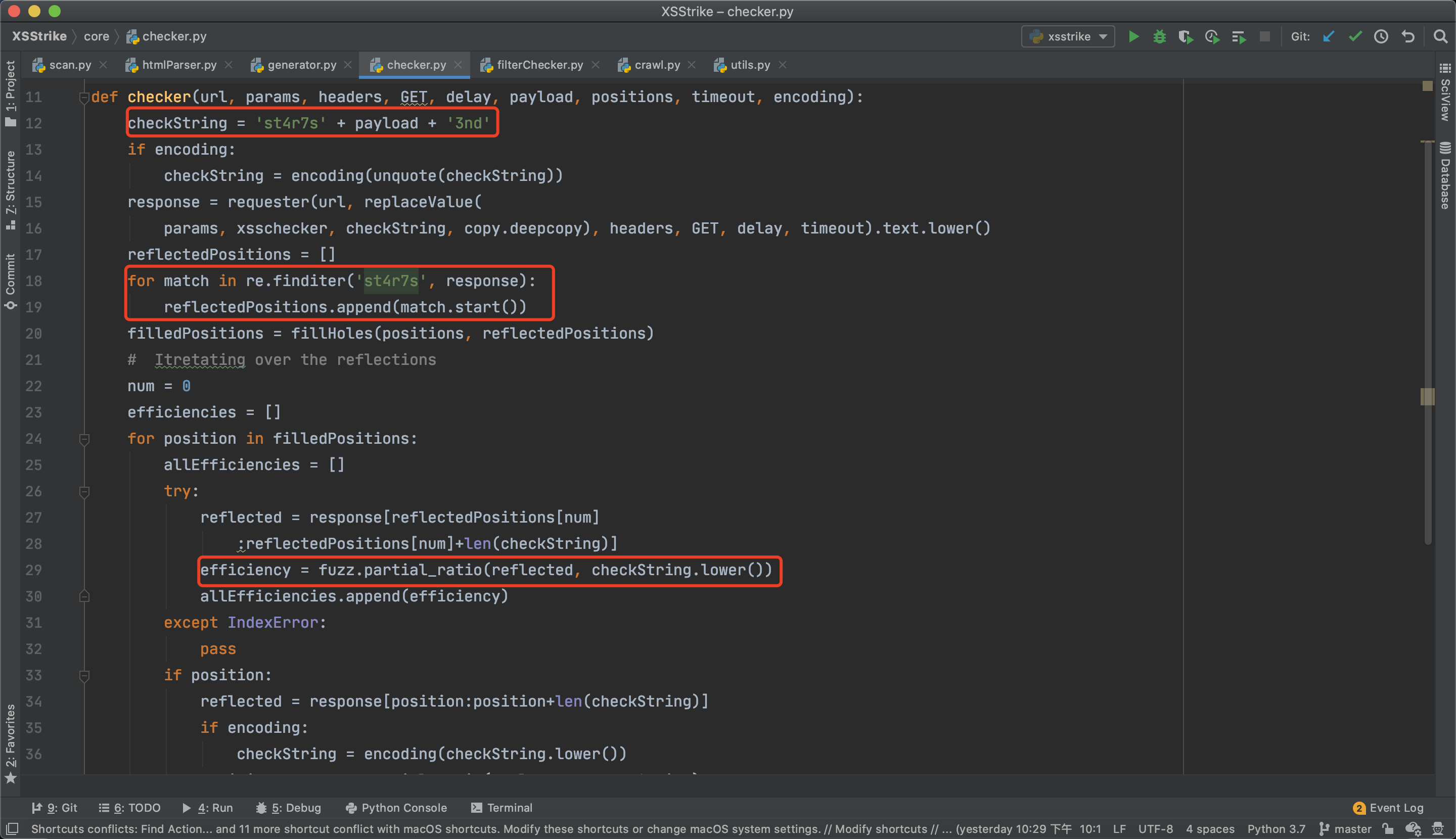
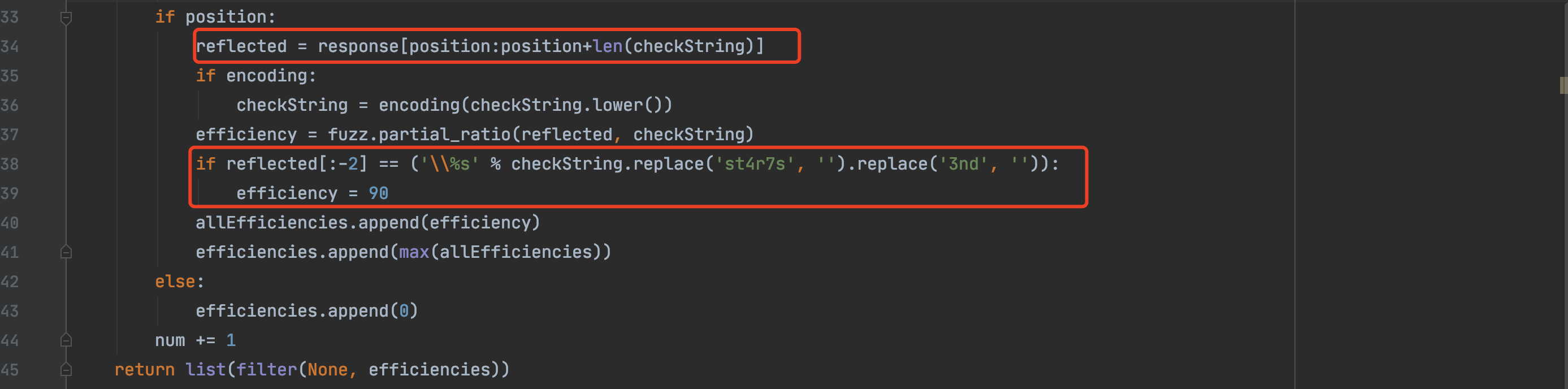
checkString中会加入测试payload,然后发送给服务器,通过响应报文查找st4r7s出现的位置,根据st4r7s的位置截取正常测试payload的长度,通过fuzz.partal_ration函数对响应报文和原始paylaod进行计算。
fuzz.partal_ration函数是一种模糊匹配算法,用于计算相似度,大致如下:

下面还会对原始的position位置进行一次运算,或者发现特殊字符并未被过滤之后权重配置为90。
取两次计算最大值返回,最终返回一个影响字典。
Payload生成
Payload生成的主要函数为generator,代码如下:
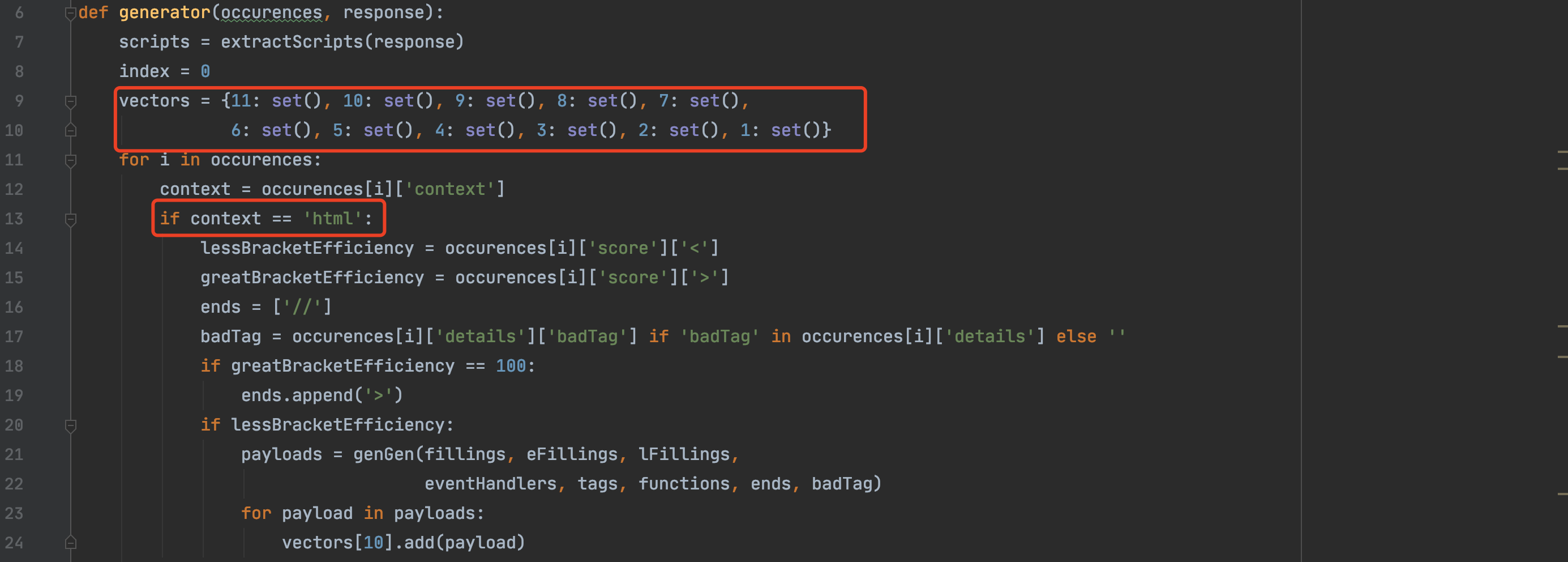
可见定义了11个set集合,用于处理可能存在的11中情况,更加智能的生成payload,提高利用效率。
首先当上下文处于html页面之中时,会尝试获取<和>的影响值,存在badTag的话则会读取出来。如果标签结束符的影响值为100的话,也就是说后台对>未做任何处理,测绘将>加入的ends变量中,然后调用genGen函数生成Payload。
跟进下genGen函数:
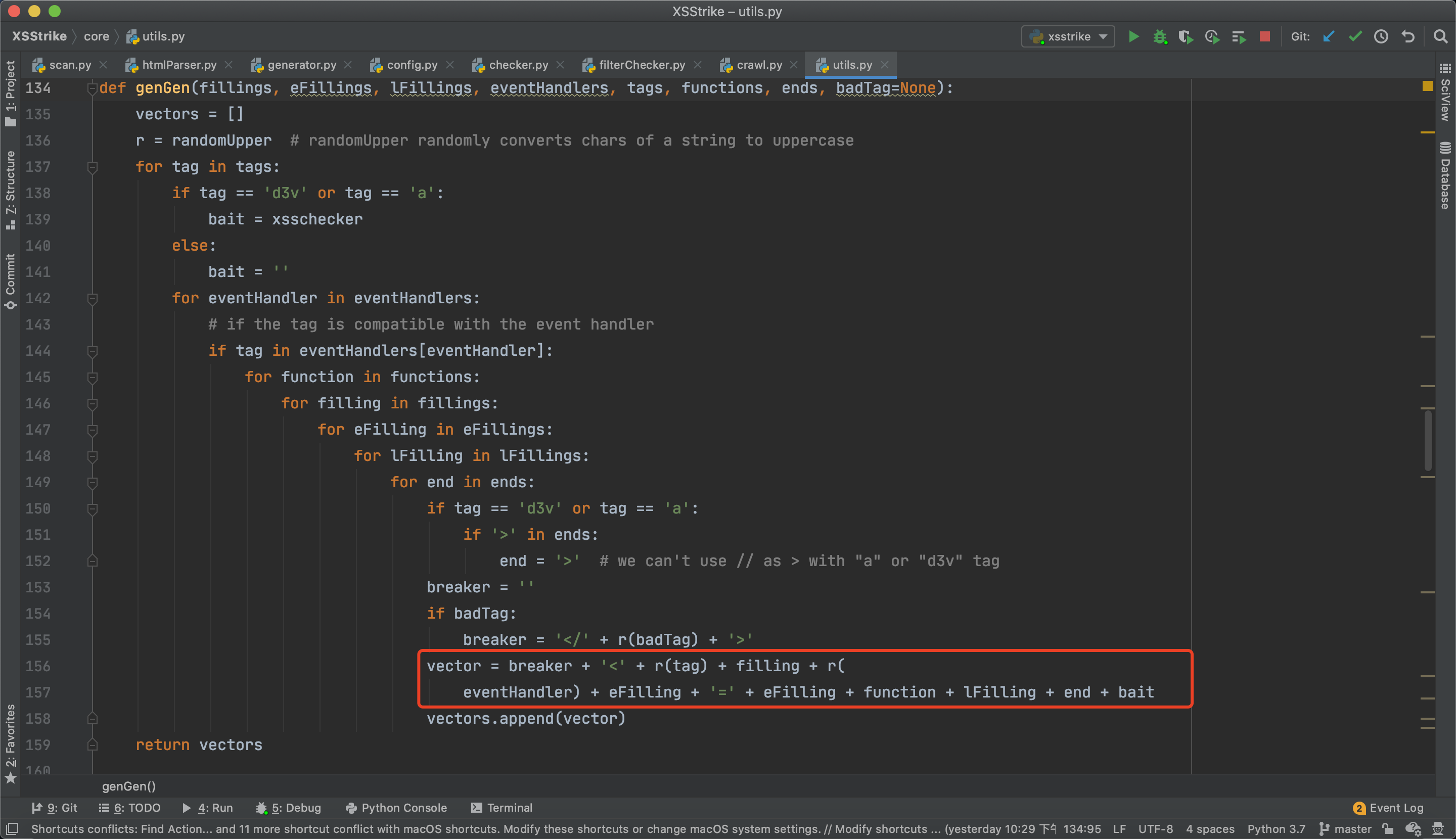
代码会for循环自定配置或者通过之前分析生成的字符,通过字符串拼接生成对应的payload。
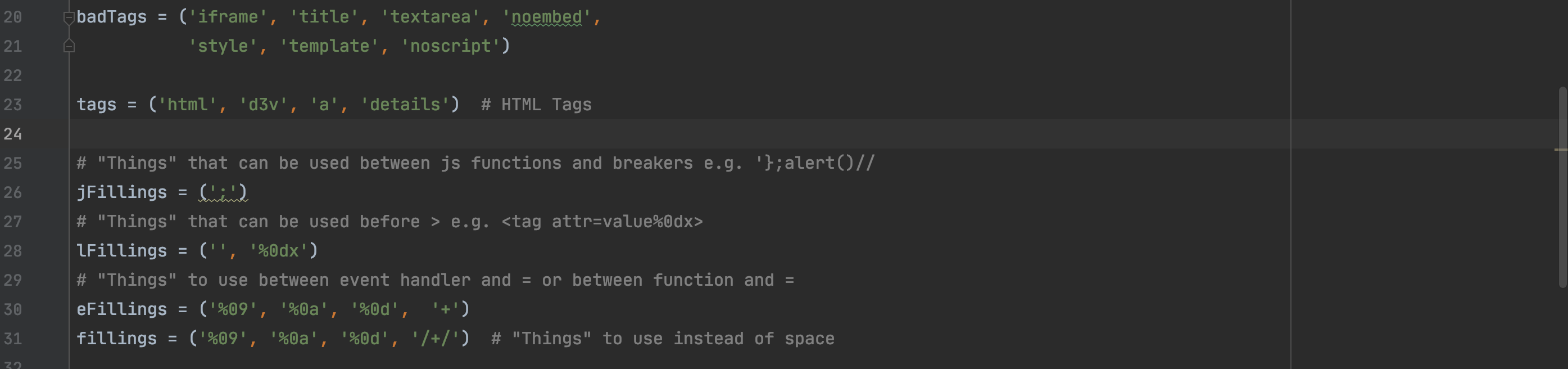
上面代码中的变量都在config.py文件中有所配置,部分如下:
当xss标记处于属性之中时,代码也会根据具体的属性生成对应的payload,和手动测试做标签闭合的方式如下,参考如下代码:
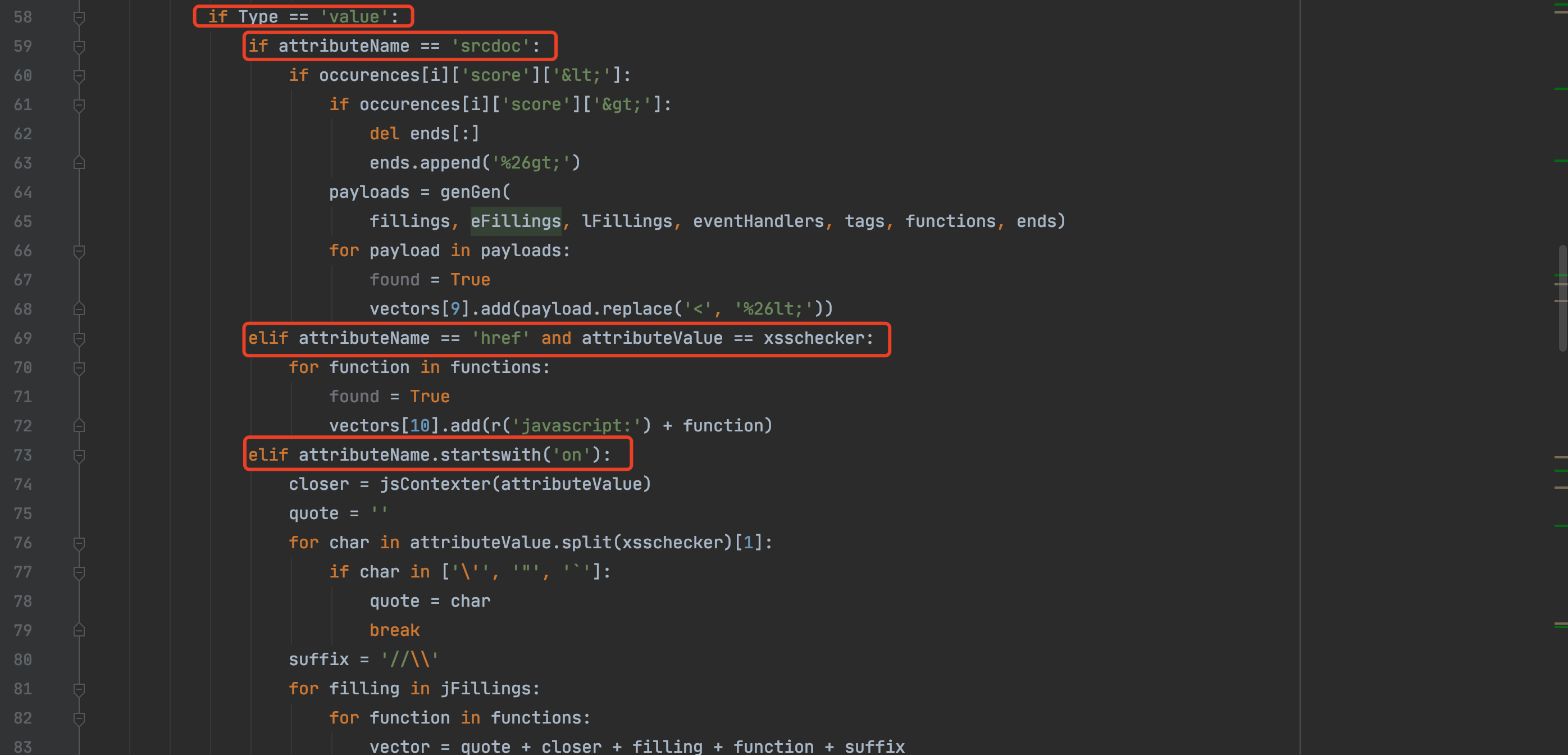
检测的条件太多了,就不一一分析了,如果出现了新的绕过方式或者新的标签属性,可以在此处进行配置,也可以进行全局配置,但是会增加检测的负荷。
XSS验证
验证逻辑如下:
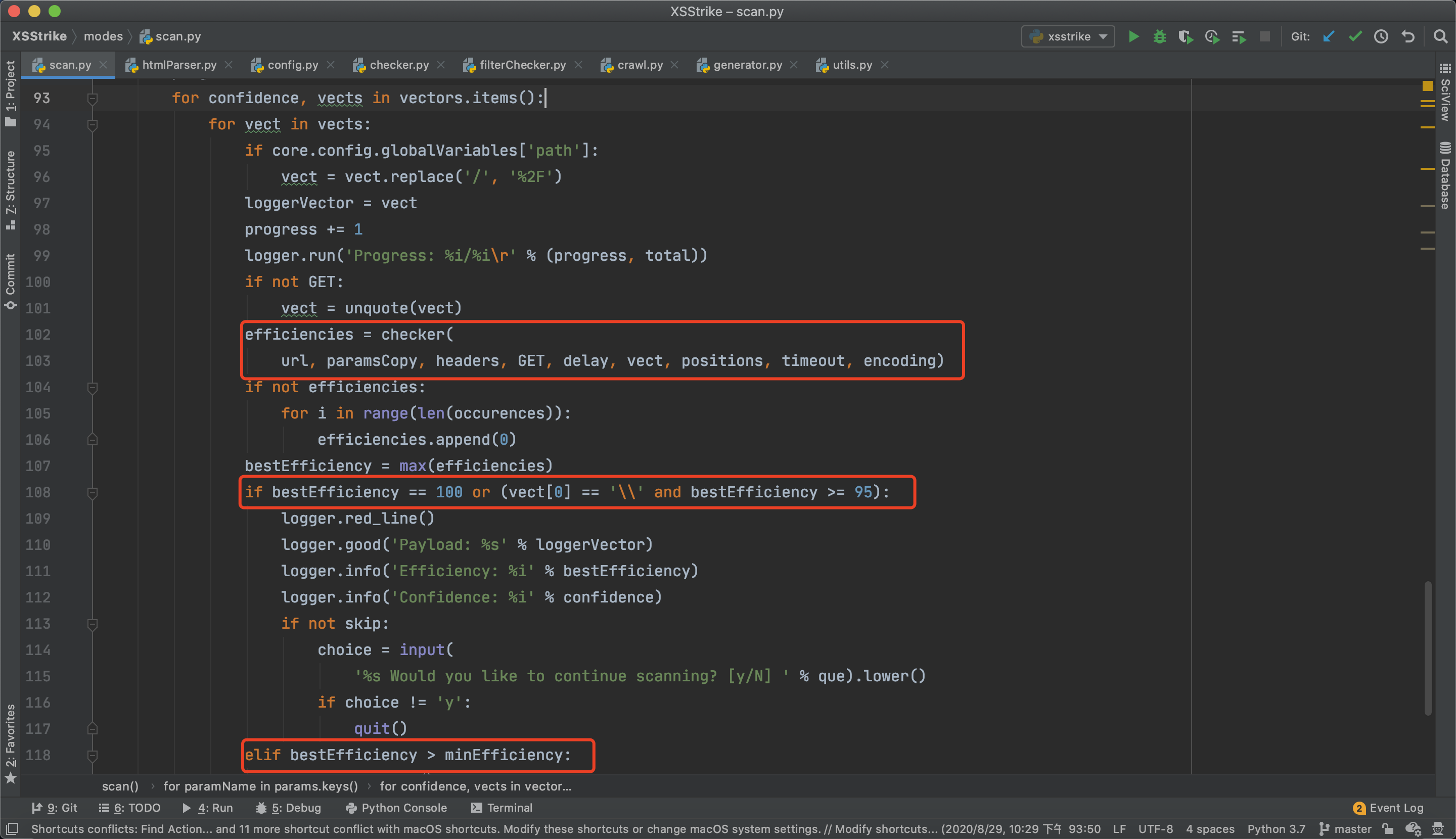
遍历生成的payload,再做一次影响检测,当完全匹配(100)或大于等于95是表示利用成功。
如果小于95的话,还会做一次比较,minEfficiency为个人设置的阀值,在config.py中配置,可以根据实际情况来配置。当大于最小阀值时,也会进行报告。
总结
orz